Automated LinkedIn Carousel Generator (RAG)¶
Status: Live demo Demo: linkedin.robiriu-dev.my.id
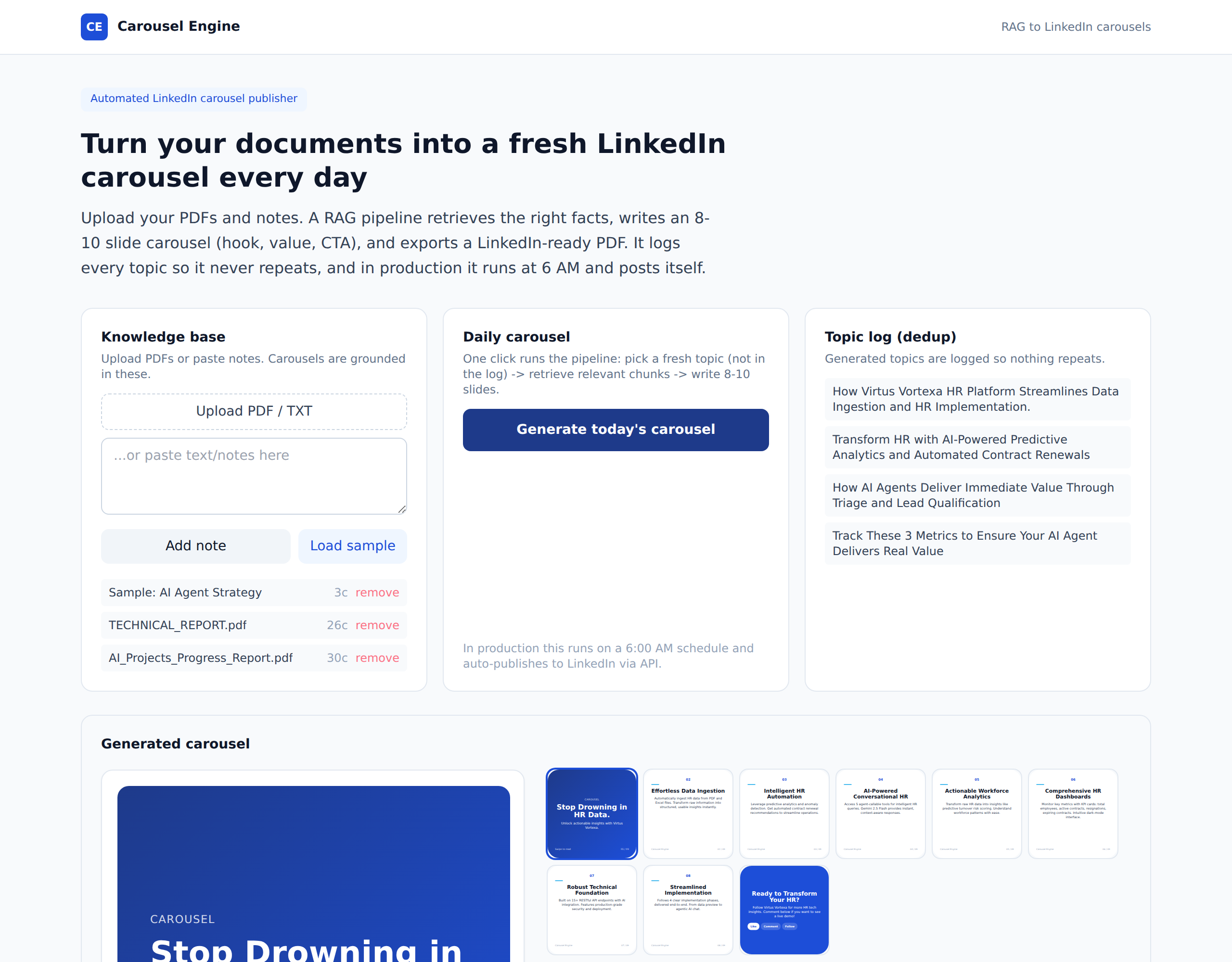
Executive Summary¶
An end-to-end Retrieval-Augmented Generation system that turns a document knowledge base into a fresh LinkedIn carousel. Upload PDFs or paste notes, and the pipeline embeds the content into a vector store, picks a fresh topic (skipping anything already in a dedup log), retrieves the most relevant chunks, and writes an 8-to-10 slide carousel (hook, value slides, CTA) grounded in the source material. The result is rendered as branded square slides and exported as a LinkedIn-ready PDF or per-slide PNGs. In production this runs on a daily 6 AM schedule and auto-publishes to LinkedIn.
How It Works¶
Upload docs ─▶ chunk + embed (text-embedding-004) ─▶ vector store
│
"Generate today" ─▶ pick fresh topic (vs dedup log) ─▶ retrieve top-k
│
Gemini 2.5 Flash ─▶ structured slide JSON (hook/value/cta)
│
render branded slides ─▶ export PDF + PNG (client-side)- Ingest — Uploaded text/PDF is chunked with sentence-aware overlap and embedded with Vertex AI
text-embedding-004into a file-backed vector store. - Topic selection — Gemini proposes a fresh, specific topic grounded in the knowledge base, explicitly avoiding the topics already in the dedup log.
- Retrieval — The chosen topic is embedded and cosine-matched against the store to pull the most relevant chunks.
- Generation — Gemini writes a strict slide-JSON carousel (one hook, several value slides, one CTA) grounded in the retrieved facts, with hashtags.
- Render & export — Slides render as 1080x1080 branded canvases; the client exports a multi-page PDF (
jsPDF+html-to-image) and per-slide PNGs.
Key Features¶
- Grounded generation — every slide is built from retrieved document chunks, with the source documents surfaced in the UI.
- Topic-dedup log — generated topics are logged so the daily output never repeats.
- Native carousel rendering — slides are rendered in-app, so no paid design API (e.g. Canva) is required, which lowers the client's running cost.
- LinkedIn-ready PDF export — one slide per page at the correct aspect ratio.
- Resilient PDF ingestion — PDF text extraction runs in a bounded child process (capped heap + timeout) so a heavy or malformed PDF can only kill the worker, never the server, returning a clean error instead.
- Scheduling (6 AM cron) and LinkedIn auto-publish (Posts API) are the thin production layer on top of the demonstrated pipeline.
Technology Stack¶
| Layer | Technology |
|---|---|
| LLM | Gemini 2.5 Flash via Vertex AI |
| Embeddings | Vertex AI text-embedding-004 (REST predict + cosine retrieval) |
| RAG | Sentence-aware chunking, file-backed vector store, dedup topic log |
| Frontend / API | Next.js 15 (App Router), TypeScript, Tailwind CSS |
| Export | jsPDF + html-to-image (client-side PDF/PNG) |
| PDF parsing | pdf-parse in an isolated, resource-bounded child process |
| Deployment | pm2 + nginx, Let's Encrypt SSL on a VPS |
Engineering Notes¶
- The chunker is guarded against an infinite-loop edge case: when the final chunk reaches the end of the text it breaks, and the cursor always advances, so arbitrarily large documents terminate cleanly.
- Embeddings are batched (5 instances per request) against the Vertex prediction endpoint with a service-account access token.
Skills Demonstrated¶
- Retrieval-Augmented Generation (chunking, embeddings, vector retrieval, grounding)
- Structured LLM output and content generation
- Client-side document rendering and PDF/PNG export
- Defensive engineering (process isolation for untrusted file parsing)
- Vertex AI integration (generation + embeddings via a GCP service account)